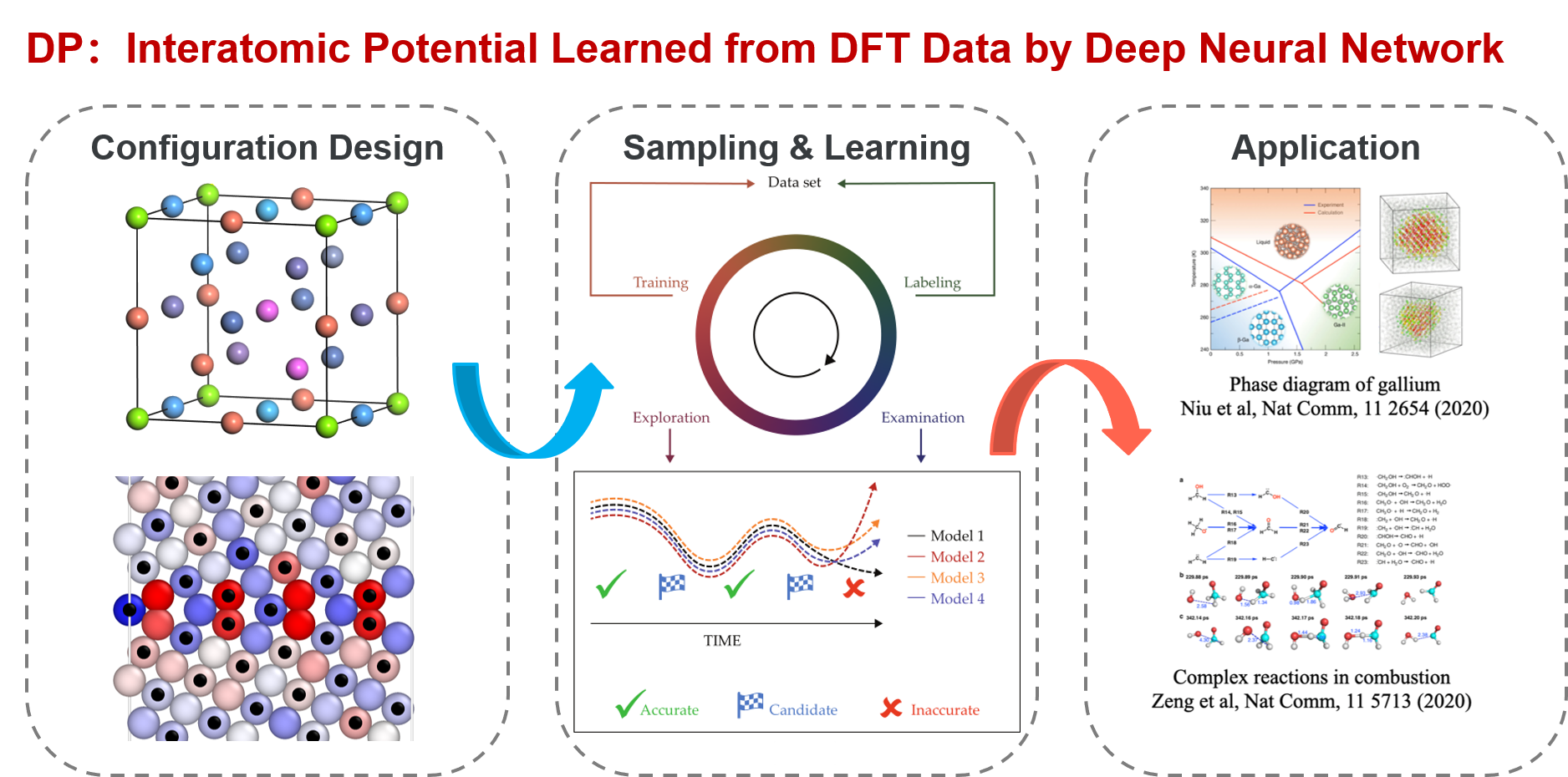
1.1. DP 实用指南
在开始一个新的 Deep Potential (DP) 项目之前,建议大家(尤其是新手)先阅读以下内容,以了解我们可以使用哪些工具、我们可能会遇到哪些问题和困难,以及我们如何顺利推进一个新的DP项目。本文的撰写重点是“局域构型空间”,这对于在处理DP项目时思考、分析和解决问题非常有用。本文分为三个主要部分:
“了解你的工具箱” :从局域构型空间的视角,简要介绍了DP方法以及DP-GEN(Deep Potential GENerator)和DP Library(Deep Potential Library)。
“了解系统的物理性质” :简单讨论了如何根据研究对象的属性设置参数,这可能对新手有所帮助。
“了解问题的边界”:探讨如何以最有效的方式生成满足我们要求的DP模型,或者我们如何将项目切割成碎片并使项目更易于实施。
1.1.1. 了解你的工具箱
了解你的工具箱意味着你不仅需要知道工具箱里有什么,这些工具可以用来做什么,还知道这种工具的局限性以及使用这些工具时可能会发生什么样的风险。
1.1.1.1. DP
深度势能 (DP) 是一种通过深度神经网络拟合原子间相互作用势(也叫势能面,potential energy surface, PES)的方法。训练数据集通常是由基于密度泛函理论(density functional theory, DFT)的方法计算获得。 相关软件是DeePMD-kit。DP方法通用性高、准确性高、计算效率高且并行效率高,是最受欢迎的机器学习势之一。
 DP
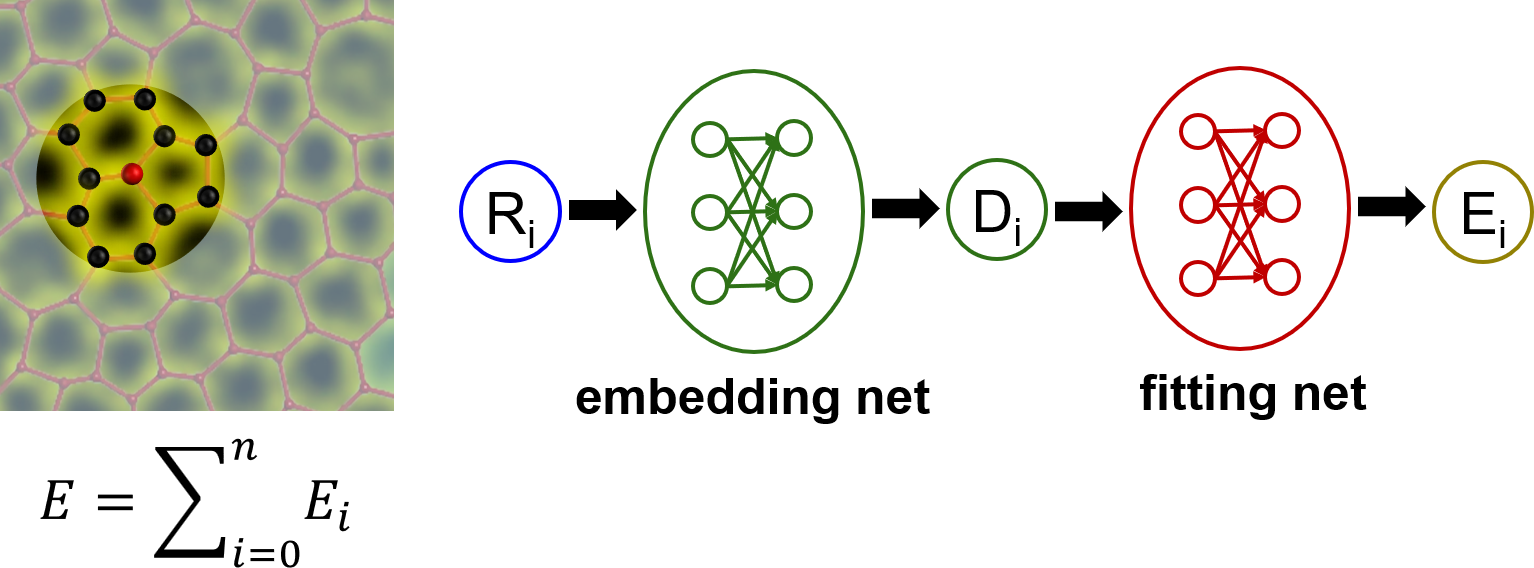
与其他机器学习势类似,DP的核心思想是系统的总能量可以划分为单个原子的势能之和,$E=∑_{i=0}^{n}E_i$, 其中每个原子的势能 $E_i$ 取决于它的局域原子构型。每个原子都由一个DP深度神经网络模型来描述 $E_i$。DP 模型由两组神经网络组成。第一组是嵌入网络,被设计为满足基本的不变性(置换、平移、旋转)要求,并将原子的局域环境编码为描述符。第二个是拟合网络,它将嵌入网络的输出映射到 $E_i$.
DP
与其他机器学习势类似,DP的核心思想是系统的总能量可以划分为单个原子的势能之和,$E=∑_{i=0}^{n}E_i$, 其中每个原子的势能 $E_i$ 取决于它的局域原子构型。每个原子都由一个DP深度神经网络模型来描述 $E_i$。DP 模型由两组神经网络组成。第一组是嵌入网络,被设计为满足基本的不变性(置换、平移、旋转)要求,并将原子的局域环境编码为描述符。第二个是拟合网络,它将嵌入网络的输出映射到 $E_i$.
 DP_Illustration
DP_Illustration
1.1.1.1.1. 构型空间
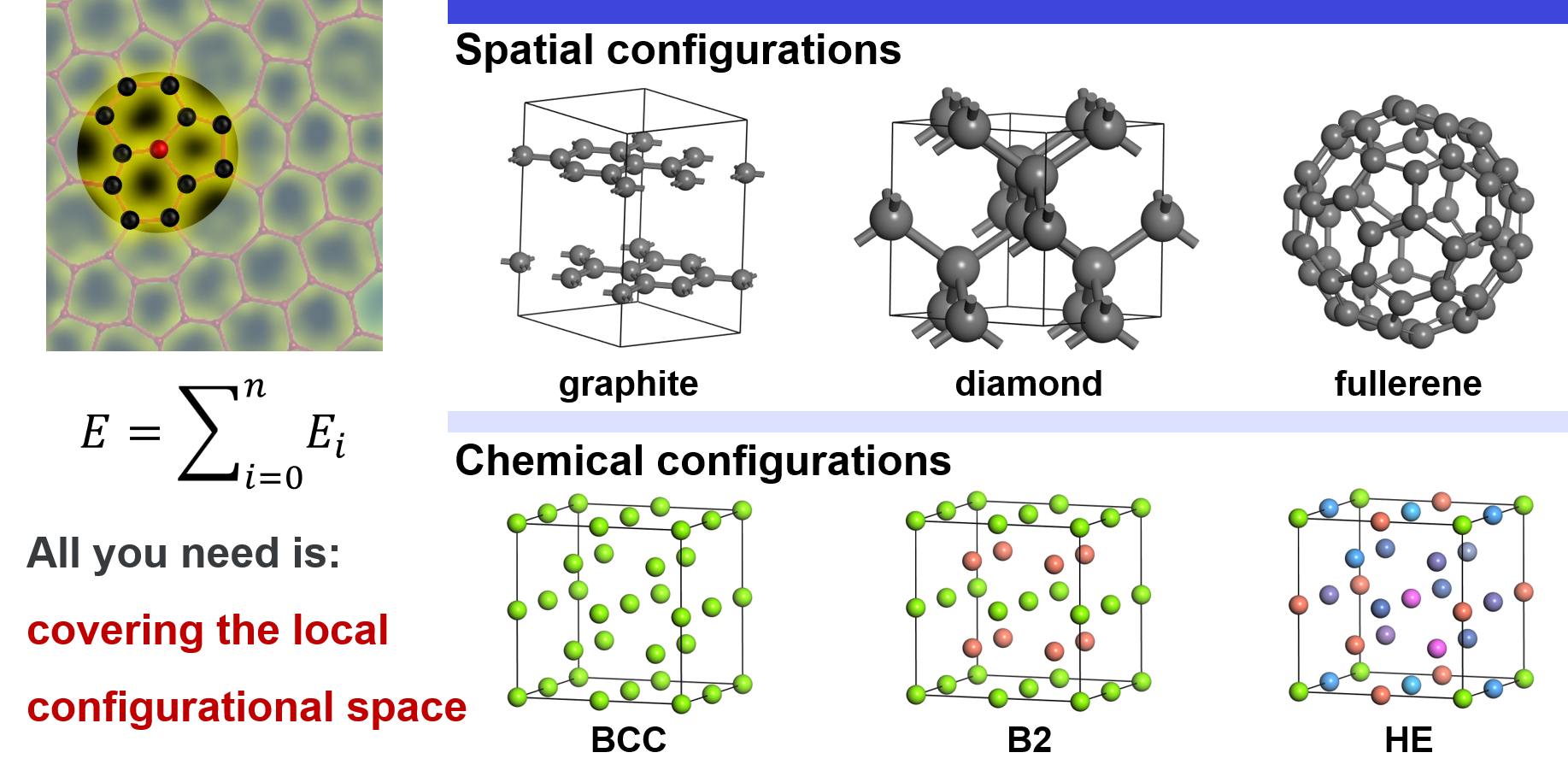
局域构型空间包括空间构型和化学构型。对于空间构型,以碳为例,可以结晶成石墨或金刚石。在石墨中,每个碳原子通过$\rm{sp}^2$键与其他三个碳原子相连 ,形成平面结构。在金刚石中, 每个碳原子通过 $\rm{sp}^3$ 键与其他四个碳相连。此外,碳还可以形成许多其他结构, 例如无定形结构,富勒烯等。除了局部原子结构的这些明显差异外,原子相对平衡位置的偏离也属于空间构型。对于化学构型,我们以理想的BCC晶格为例。在最简单的情况下,所有晶格位置都被同一个原子占据,例如Ti。另一种情况是四角被Ti占据,内中心被Al占据,是B2结构的有序TiAl化合物。因此,Ti周围的局域化学环境发生了变化。在更复杂的情况下,所有位点可能被不同的原子随机占据,例如高熵合金,可能导致巨大的化学构型空间。需要强调的是,这种划分为了便于理解做的概念性划分。实际上,空间构型和化学构型是耦合在一起的,不能明确分离开。
 Configuration
Configuration
1.1.1.1.2. 采样方法
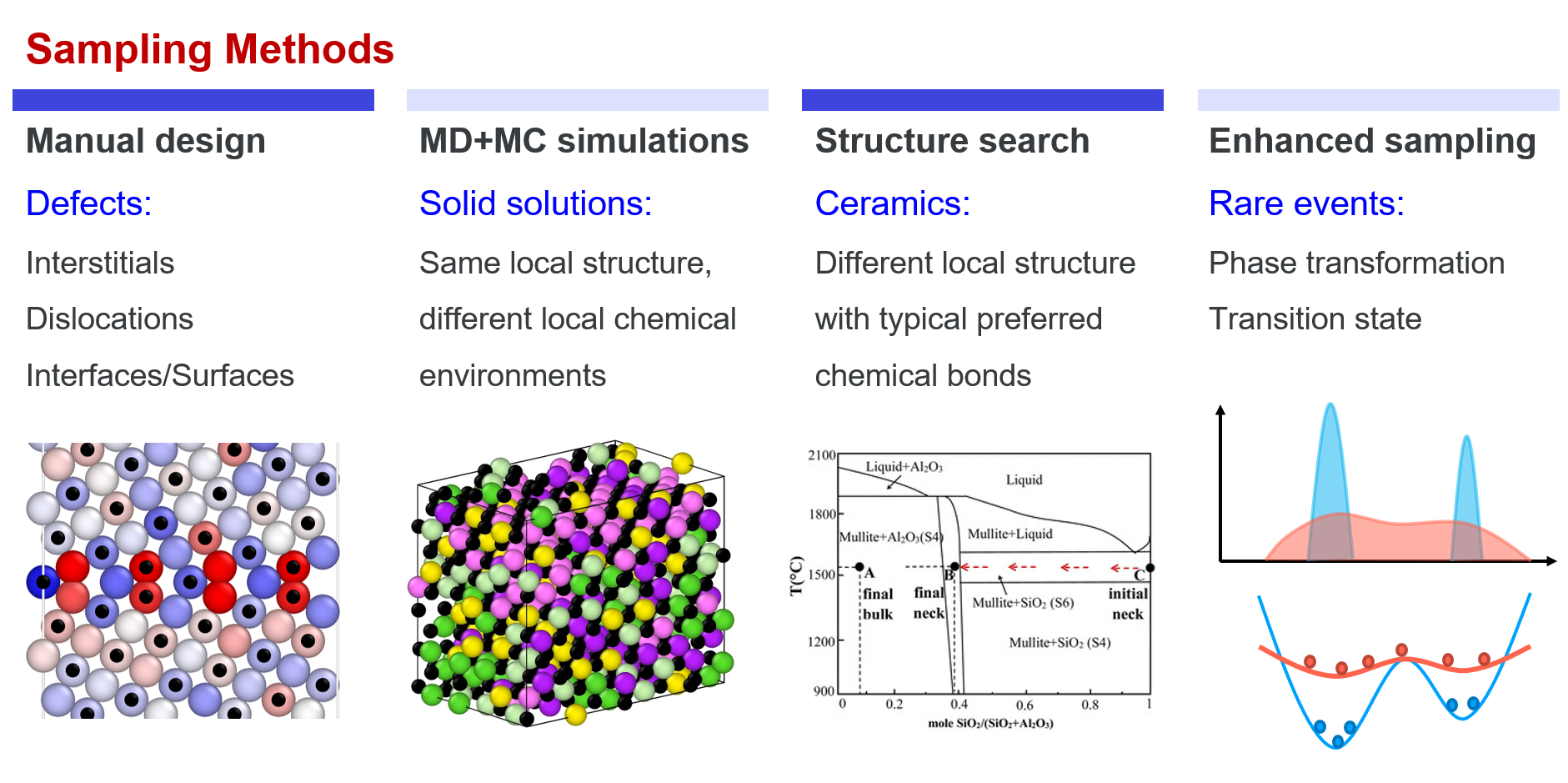
综上所述,在开发新的DP模型时”我们所需要做的就是尽可能覆盖足够的局域构型空间”。这里介绍实践中常用的局域构型空间采样方法。粗略地,这些方法可以分为四类:手动设计、MD+MC模拟、结构搜索和增强采样。
手动设计 尽管可以使用多种多样的方法来辅助采样,但手动设计仍然是最重要的采样方法之一,尤其是对于缺陷结构的采样。例如,间隙、空位、层错、位错、表面、晶界的初始结构几乎总是需要人为构建。在其他一些情况下,初始结构也需要由专家构建,例如不同材料之间的相界面、吸附结构等。
MD+MC模拟 MD和MC模拟是对局域构型空间进行采样的有效方法,也是最易实现的方法。例如,原子在固体中围绕平衡位置附近的振动(MD),液体中的局域环境的变化(MD),在固溶体中交换相似原子(MD+MC)等。MD/MC 模拟可以覆盖的构型空间取决于模拟的温度和时间。在实践中,也可以采用其他加速MD方法来更有效地辅助采样。
结构搜索 结构搜索方法,例如CALYPSO,USPEX,有助于探索具有强方向键的材料的合理结构,(例如大多数陶瓷,以及一些其他无机非金属材料碳、硼、磷等) 或高压下的未知结构。在这种情况下,手动构建和MD+MC遍历能力不足。由于我们需要覆盖足够的构型空间,因此在结构搜索过程中,不仅需要收集稳态结构来丰富我们的数据集,还需要那些能量不是很高的亚稳态结构。 -增强采样 增强采样是一种对稀有事件进行采样的有效方法,通常用于对PES周围的鞍点进行采样。在一个系统中,构型被采样的概率是 $p \propto exp(-U/k_BT)$。因此,高能态,例如相变中间态、反应的过渡态,很难通过MD模拟进行采样。在增强采样方法中,通常会添加偏置势以使PES变平,从而增强高能态被访问的概率。
 Sampling_methods
Sampling_methods
1.1.1.1.3. 局限性和风险
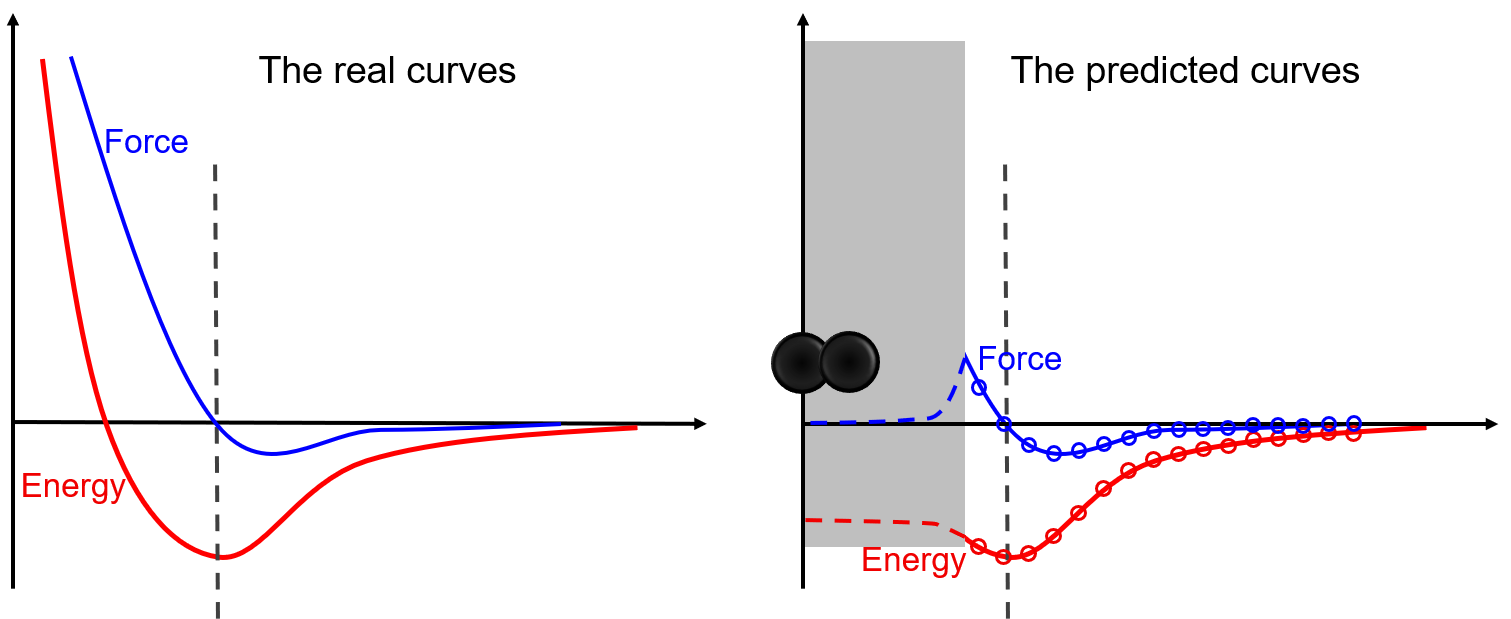
由于机器学习模型有较好的表示和拟合能力,机器学习势比传统经验势更精确。但是,硬币总有正反面。几乎所有机器学习都有一个典型的缺点,即样本分布外的外推能力低。如下图所示,该模型在数据集覆盖的区域拟合得非常好,而在数据集未覆盖的区域预测了完全错误的结果。在这个例子中,由于靠近原子核区域缺乏排斥力,两个原子可能会非物理地结合在一起。通常,在采样期间,彼此靠得非常近的原子对是不在数据集中的。为了避免这种非物理结合,可以在这个区域人为地设计一些排斥势,或者在数据集中添加双原子构型,让模型自己学习近核排斥。
 Risks
这只是一个简单的例子来说明如果训练数据集在局域构型空间上的覆盖率很差,模拟中可能发生的非物理现象的风险。这里说明机器学习势的这种风险,并不是鼓励人们在训练DP模型时覆盖所有构型空间。相反,在“了解问题的边界”一节中,我们鼓励大家对研究问题所在的构型空间区域进行采样。这意味着训练一个对所研究问题足够准确的DP模型即可。理论上讲,在某些情况下,构型空间可能会太大而无法完全采样。所以, “训练一个全局可用的稳定DP模型并不是一件容易的事”。
Risks
这只是一个简单的例子来说明如果训练数据集在局域构型空间上的覆盖率很差,模拟中可能发生的非物理现象的风险。这里说明机器学习势的这种风险,并不是鼓励人们在训练DP模型时覆盖所有构型空间。相反,在“了解问题的边界”一节中,我们鼓励大家对研究问题所在的构型空间区域进行采样。这意味着训练一个对所研究问题足够准确的DP模型即可。理论上讲,在某些情况下,构型空间可能会太大而无法完全采样。所以, “训练一个全局可用的稳定DP模型并不是一件容易的事”。
1.1.1.2. DP-GEN
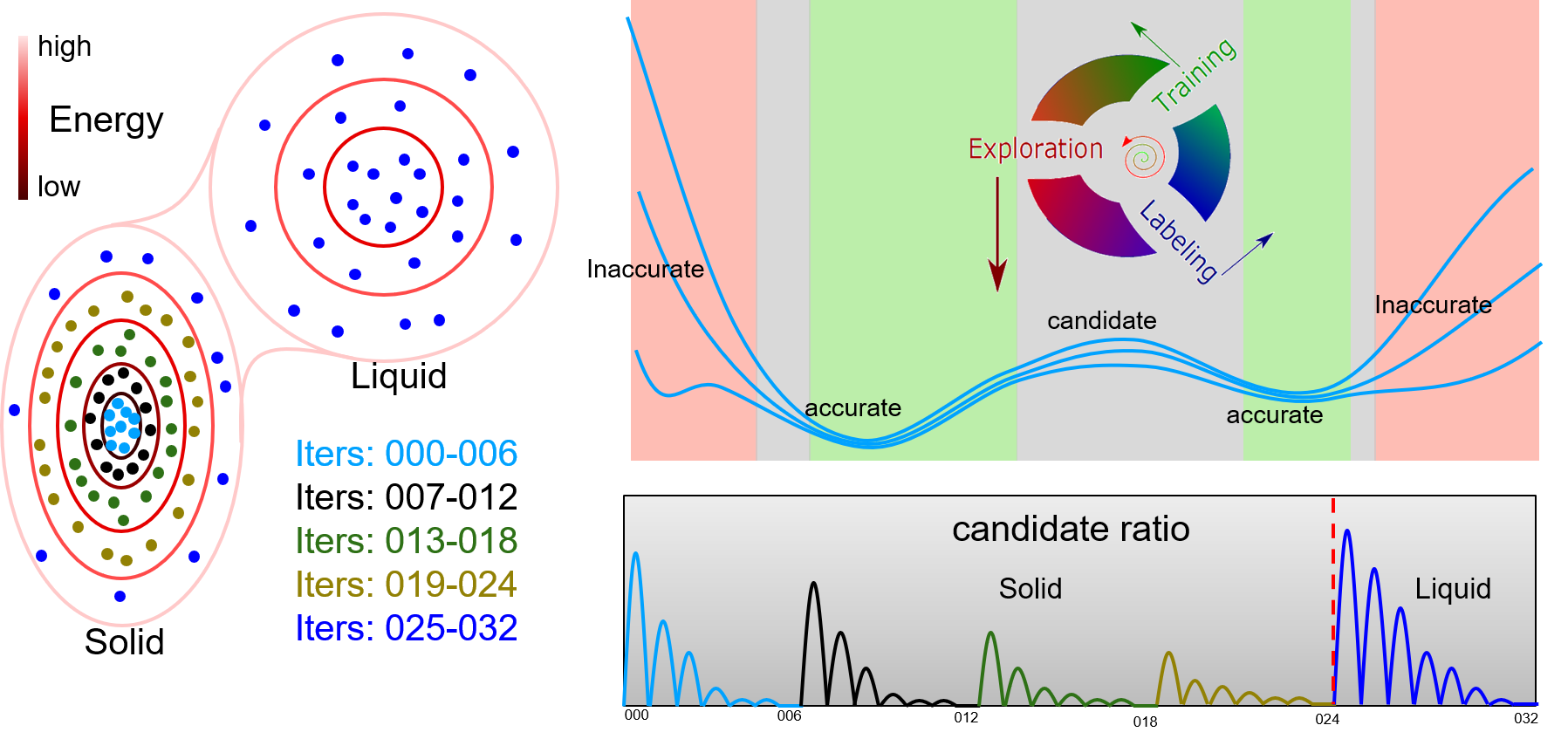
DP-GEN是“Deep Potential GENerator”的缩写,是在同步学习框架下设计的DP模型自动生成器。在DP-GEN中,数据集的增加和DP模型的改进是同时进行的。DP-GEN软件可以自动管理整个流程,包括准备作业脚本 (例如训练模型,探索构型空间、检查现有模型在构型空间的准确性并筛选出准确性不足的候选构型,以及通过DFT计算给候选构型打标签), 将作业提交到云计算或其他高性能计算集群上, 并监控工作状态。下图显示了一个典型的DP-GEN自动迭代流程,包括三个典型的过程:
训练一组DP模型(通常是四个),这些模型将被用来探索构型空间并检查探索的构型是否能够被准确预测。
采用其中一个DP模型探索构型空间,并通过比较不同DP模型之间的预测偏差来检查每个构型的预测精度。
选择一些预测精度较低的构型作为候选构型,并通过DFT计算给候选构型打标签。
最初,需要提供一个包含数百至数千个DFT计算获得的数据集(初始数据集),之后便可以启动并连续运行DP-GEN的自动迭代流程。初始数据集可以由DP-GEN软件生成 (例如通过使用”init_bulk”, “init_surf”模块,或者”autotest” 模块), 也可以自己生成。在DP-GEN迭代过程中,数据集对构型空间的覆盖范围是有限的,尤其是在前几轮迭代中。正如在“局限性和风险”一节中所讲,在此时数据集上训练的DP模型能力也是受限的。当构型在已探索区域内时,模型能够准确预测该构型;当构型稍微超出已探索区域的边界时,预测结果准确性不足;当构型远离已探索区域时,预测则是错误的。此外,当使用DP模型探索构型空间时(例如通过MD),当构型远离已探索区域时,可能会出现非物理构型。为了避免选择非物理构型,只选择已探索区域边界附近的那些构型作为候选。因此,选择候选构型时需要设置预测偏差的上下限。在实践过程中,如果存在可用的经验势,则可以使用经验势来进行采样,这将更加稳健,并且可以避免出现非物理构型。在这种情况下,可以将预测偏差的上限设置为一个较大的值。通过改变采样方法或采样参数,探索区域的边界随着迭代而扩展,例如增加MD温度和模拟时间。
 DP-GEN
DP-GEN
1.1.1.3. DP Library
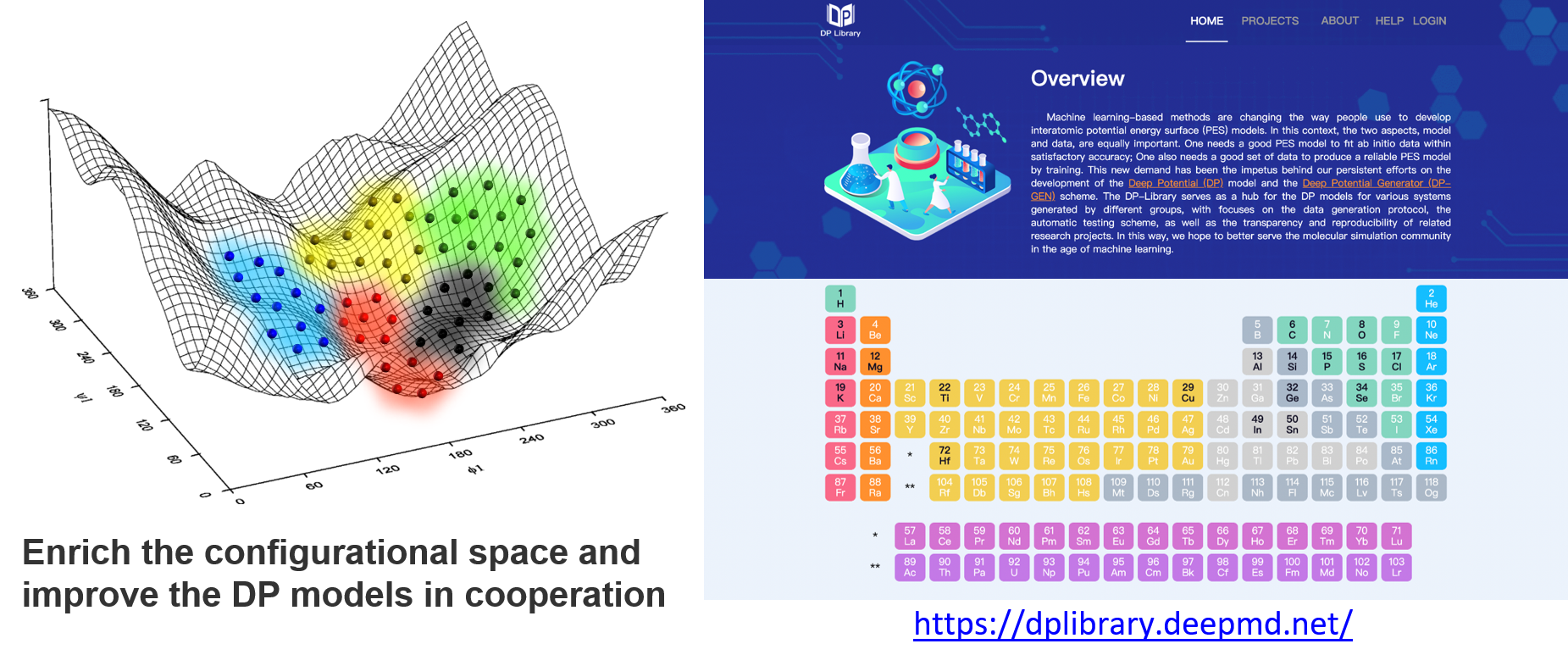
DFT方法计算量大且非常耗时。因此,我们建立了DP library共享DFT计算源数据,以避免由于重复计算造成的浪费,并鼓励大家贡献自己的DFT源数据,丰富数据集,并不断改进DP模型。有了这个基础设施,对构型空间不同区域的采样可以由不同的研究人员贡献,如下图所示。当数据集更加丰富时,可以自动重新训练和改进DP模型。最后,在DP library上会得到许多DP模型。这些模型适用于大多数问题,以便研究人员可以将精力集中于应用DP模型解决实际问题,而不是耗费在构建DP模型中。当我们需要一个DP模型时,可以按照以下步骤检查应该做什么:
检查是否存在训练好的模型,直接从DP library下载模型
如果不存在,检查是否DP library上是否存在可用的DFT数据集,自己添加一些数据并训练一个模型
如果既没有训练好的模型也没有任何有价值的数据,则从头开始生成数据并从头开始训练模型
如果你愿意,将DFT源数据和模型贡献给DP library,以方便更多人使用你的数据或者模型。
 DP_LIB
DP_LIB
1.1.2. 了解系统的物理性质
当实施一个DP项目时,有许多参数需要确定。例如:生成初始数据集时,形变量和位移量;利用分子动力学采集构型空间时,温度、压强和模拟步数等。虽然可以从其他地方复制一些脚本并且在不怎么修改参数的情况下运行DP-GEN,但在实践中这并不是一个好办法。我们需要了解研究体系的物理性质以便帮助设计各种参数,获得更优的实践经验。
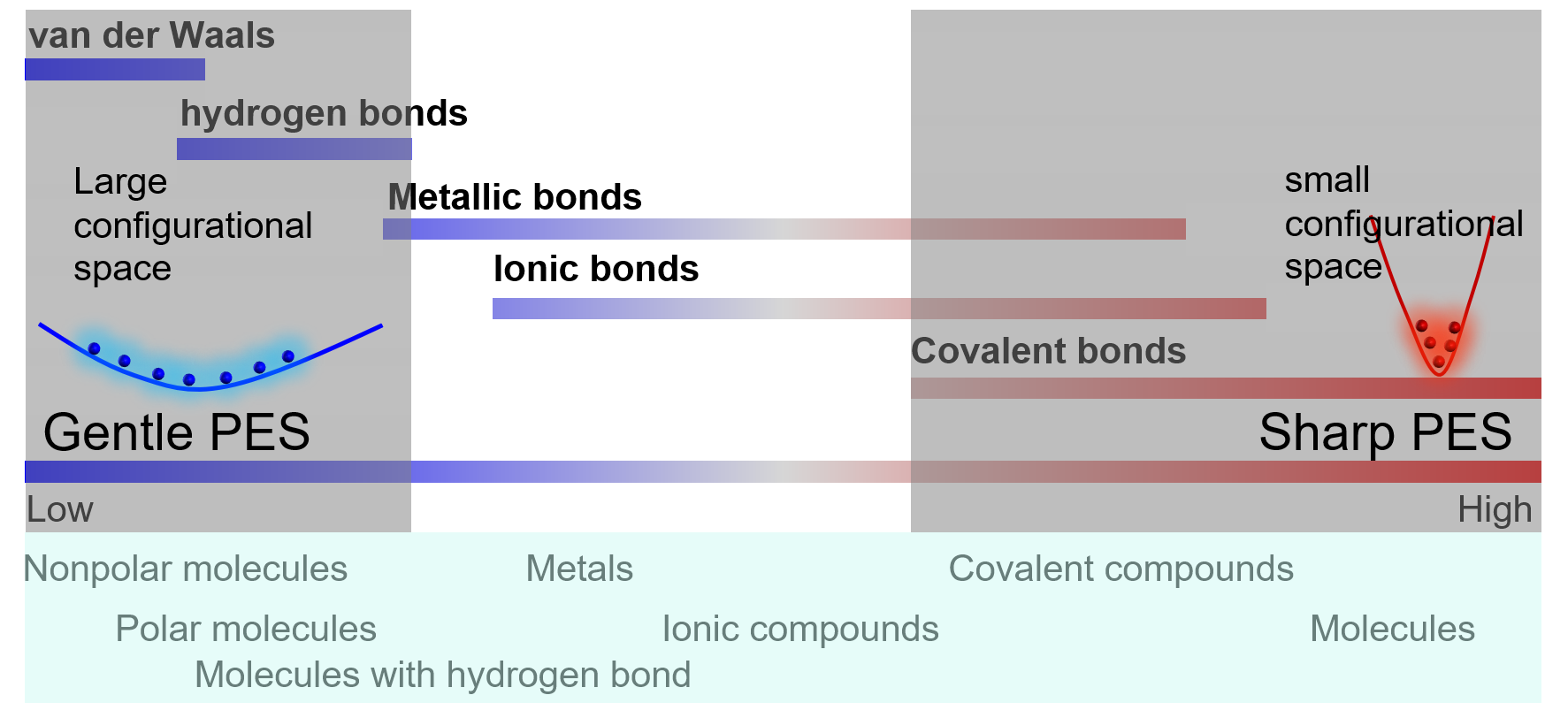
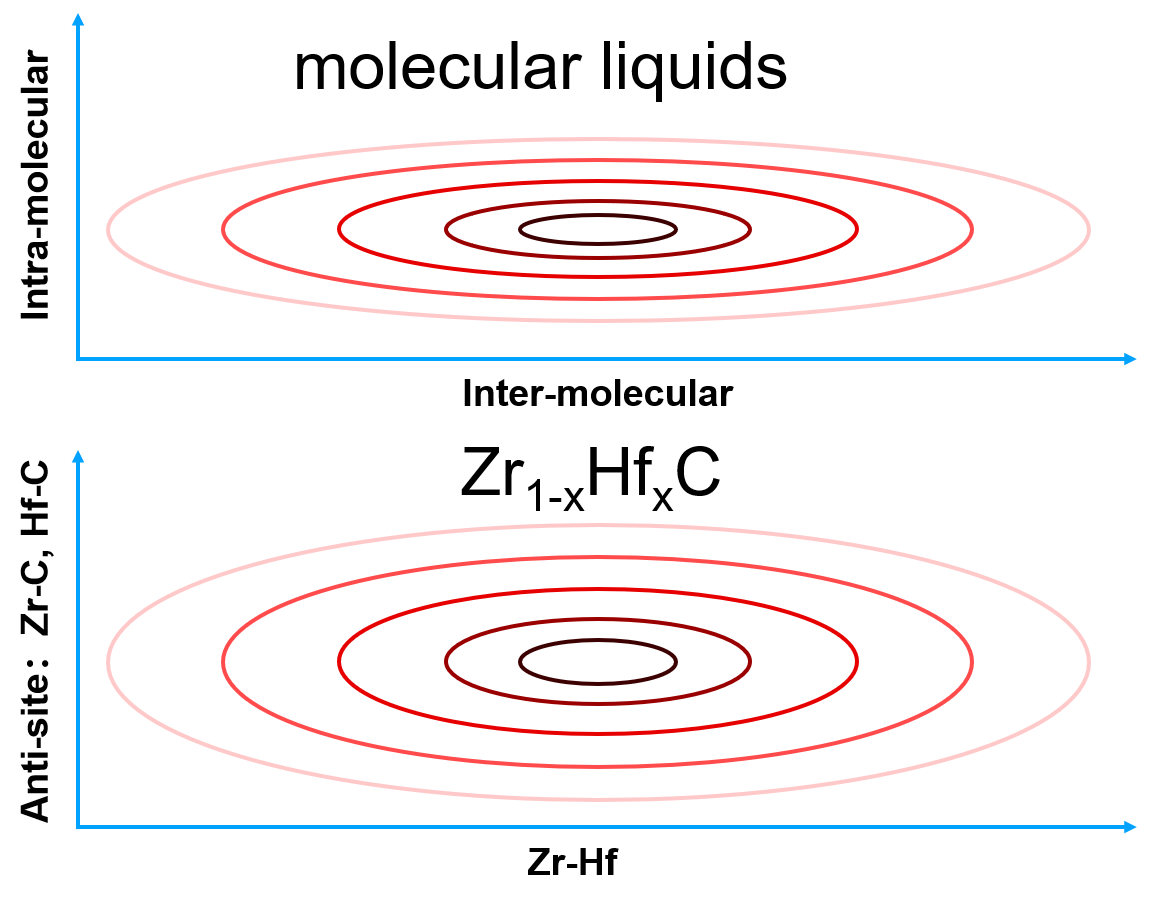
局域构型空间的势能面形状取决于与之相关的键合强度。下图显示了化学键强度图谱。与弱化学键的相关的构型空间对应的局部势能面形状是相对平缓的,而与强化学键相关的构型空间对应的局部势能面形状是尖锐的。
 bond_nature
1.尖锐区域:势能面中的深谷
-单个分子的振动
-固体中原子的振动
2.平缓区域:势能面中的浅坑
-液体中原子或分子的运动
-固溶体
3.势垒区域:
-相变路径中间态
-反应的过渡态
以液体分子为例。分子内的化学键对应一个尖锐的势能面,对应于构型空间中原子在平衡位置附近的振动。振动的特征时间非常短(~fs),因此在短时间MD模拟中,对构型空间的采样可能就比较充分了。相比之下,分子间化学键对应一个平缓的势能面,在构型空间中体积较大。分子间相互移动的特征时间较大(-ps),因此构型空间中的充分采样需要长时间MD模拟,或从不同构型开始的许多短时间MD模拟。类似的考虑也适用于化学构型空间。以$\rm{Zr}_{1−x}{Hf}_xC$为例,众所周知,改变Zr-Hf并不会显著改变能量,这与平缓的势能面相对应,因此就需要较多的MC步数来对构型空间进行采样。然而,反位缺陷Zr-C或Hf-C的能量非常高。因此,可能不需要对反位缺陷进行采样。
bond_nature
1.尖锐区域:势能面中的深谷
-单个分子的振动
-固体中原子的振动
2.平缓区域:势能面中的浅坑
-液体中原子或分子的运动
-固溶体
3.势垒区域:
-相变路径中间态
-反应的过渡态
以液体分子为例。分子内的化学键对应一个尖锐的势能面,对应于构型空间中原子在平衡位置附近的振动。振动的特征时间非常短(~fs),因此在短时间MD模拟中,对构型空间的采样可能就比较充分了。相比之下,分子间化学键对应一个平缓的势能面,在构型空间中体积较大。分子间相互移动的特征时间较大(-ps),因此构型空间中的充分采样需要长时间MD模拟,或从不同构型开始的许多短时间MD模拟。类似的考虑也适用于化学构型空间。以$\rm{Zr}_{1−x}{Hf}_xC$为例,众所周知,改变Zr-Hf并不会显著改变能量,这与平缓的势能面相对应,因此就需要较多的MC步数来对构型空间进行采样。然而,反位缺陷Zr-C或Hf-C的能量非常高。因此,可能不需要对反位缺陷进行采样。
 PES
为了简单起见,以Al为例来阐述材料的物理性质与DP-GEN参数之间的关系。
1.首先需要生成初始数据集。例如,使用DP-GEN中提供的“init_bulk”方法。在该方法中,我们需要设置整体的单轴压缩/膨胀、晶格变形以及原子移动的范围。通常,对于固体材料而言,从室温到熔点的体积膨胀约为5%,沿每个方向约为2%。因此,除了在高压区域外,将线性压缩/膨胀范围设置为±2%通常可以很好地覆盖固体边界。随机的晶格变化也可以设置为类似的值,例如,对于每个应变模式可以取为[-3%,3%]间的随机数。原子位置移动的值可参考最近邻的键长(例如<1%d,其中d为键长)。一般情况下可以设为0.01Å。
2.当使用DP-GEN自动迭代时,我们一般通过不断增加温度和压强进行MD模拟对构型空间进行采样。温度的设置可以参考Al的熔点Tm (~1000 K)与此同时,关于压强的设置可以参考 铝的体模量B (~80 GPa)。例如,可以将温度设置为四组:[0.0Tm,0.5Tm],[0.5Tm,1.0Tm],[1.0Tm,1.5Tm]和[1.5Tm,2.0Tm]。在每组中可以选择几个温度值,例如,可以将[0.0Tm,0.5Tm]分成[0.0Tm,0.1Tm,0.2Tm,0.3Tm,0.4Tm](实际上,0.0Tm是无用的)。在MD模拟的过程中,压力会发生波动,在小体系中,其幅度可能约为体模量的1%。因此,将压强设定为[0.00B、0.03B、0.06B、0.09B]通常就足够了。添加-0.01B可能有助于固体结构的采样,一般不会为液体结构设置负压,以避免模拟盒子持续膨胀的风险。
3.选择候选构型的上下限(“trust_level_low”和“trust_level_high”)可能取决于体系中最强的化学键。例如,分子体系中的值可能高于金属体系中的值。在固体中,上限和下限约为力的RMSE(约化均方误差)$\sqrt{\sum f_i^2} $的0.2和0.5。此外,上下限取值也可参考熔点或体模量,因为力与这些性质成正比。例如,对于Al来说DP-GEN的“trust_level_low”为0.05 eV/Å,而W的“trust_level_low”为0.15 eV/Å,其值是Al的三倍。W的熔点(~3600 K)也是Al熔点(~1000 K)的约三倍。当对照上述键合强度图谱时,这些物性可以作为好的参考指标,用来辅助设定DP-GEN的参数。然而,这些标准可能不适用于液体分子。这是由于液体分子内键合很强,即使它们的熔点很低,但仍然需要相对较高的上下限值。
PES
为了简单起见,以Al为例来阐述材料的物理性质与DP-GEN参数之间的关系。
1.首先需要生成初始数据集。例如,使用DP-GEN中提供的“init_bulk”方法。在该方法中,我们需要设置整体的单轴压缩/膨胀、晶格变形以及原子移动的范围。通常,对于固体材料而言,从室温到熔点的体积膨胀约为5%,沿每个方向约为2%。因此,除了在高压区域外,将线性压缩/膨胀范围设置为±2%通常可以很好地覆盖固体边界。随机的晶格变化也可以设置为类似的值,例如,对于每个应变模式可以取为[-3%,3%]间的随机数。原子位置移动的值可参考最近邻的键长(例如<1%d,其中d为键长)。一般情况下可以设为0.01Å。
2.当使用DP-GEN自动迭代时,我们一般通过不断增加温度和压强进行MD模拟对构型空间进行采样。温度的设置可以参考Al的熔点Tm (~1000 K)与此同时,关于压强的设置可以参考 铝的体模量B (~80 GPa)。例如,可以将温度设置为四组:[0.0Tm,0.5Tm],[0.5Tm,1.0Tm],[1.0Tm,1.5Tm]和[1.5Tm,2.0Tm]。在每组中可以选择几个温度值,例如,可以将[0.0Tm,0.5Tm]分成[0.0Tm,0.1Tm,0.2Tm,0.3Tm,0.4Tm](实际上,0.0Tm是无用的)。在MD模拟的过程中,压力会发生波动,在小体系中,其幅度可能约为体模量的1%。因此,将压强设定为[0.00B、0.03B、0.06B、0.09B]通常就足够了。添加-0.01B可能有助于固体结构的采样,一般不会为液体结构设置负压,以避免模拟盒子持续膨胀的风险。
3.选择候选构型的上下限(“trust_level_low”和“trust_level_high”)可能取决于体系中最强的化学键。例如,分子体系中的值可能高于金属体系中的值。在固体中,上限和下限约为力的RMSE(约化均方误差)$\sqrt{\sum f_i^2} $的0.2和0.5。此外,上下限取值也可参考熔点或体模量,因为力与这些性质成正比。例如,对于Al来说DP-GEN的“trust_level_low”为0.05 eV/Å,而W的“trust_level_low”为0.15 eV/Å,其值是Al的三倍。W的熔点(~3600 K)也是Al熔点(~1000 K)的约三倍。当对照上述键合强度图谱时,这些物性可以作为好的参考指标,用来辅助设定DP-GEN的参数。然而,这些标准可能不适用于液体分子。这是由于液体分子内键合很强,即使它们的熔点很低,但仍然需要相对较高的上下限值。
1.1.3. 了解问题的边界
请记住,“训练一个全局可用的稳定DP模型并不是一件容易的事”。通常,我们只需要一个符合我们要求的DP模型。对于不同的任务,数据集需要覆盖的构型空间范围是不同的。下面举一个例子来说明:
1.我们对Al的室温弹性性能感兴趣
-我们对Al弹性性质的温度依赖性更感兴趣
2.我们对Al的熔点感兴趣
-我们对Al的凝固过程更感兴趣
3.我们对铝的缺陷(例如,空位、间隙、位错、表面、晶界)感兴趣
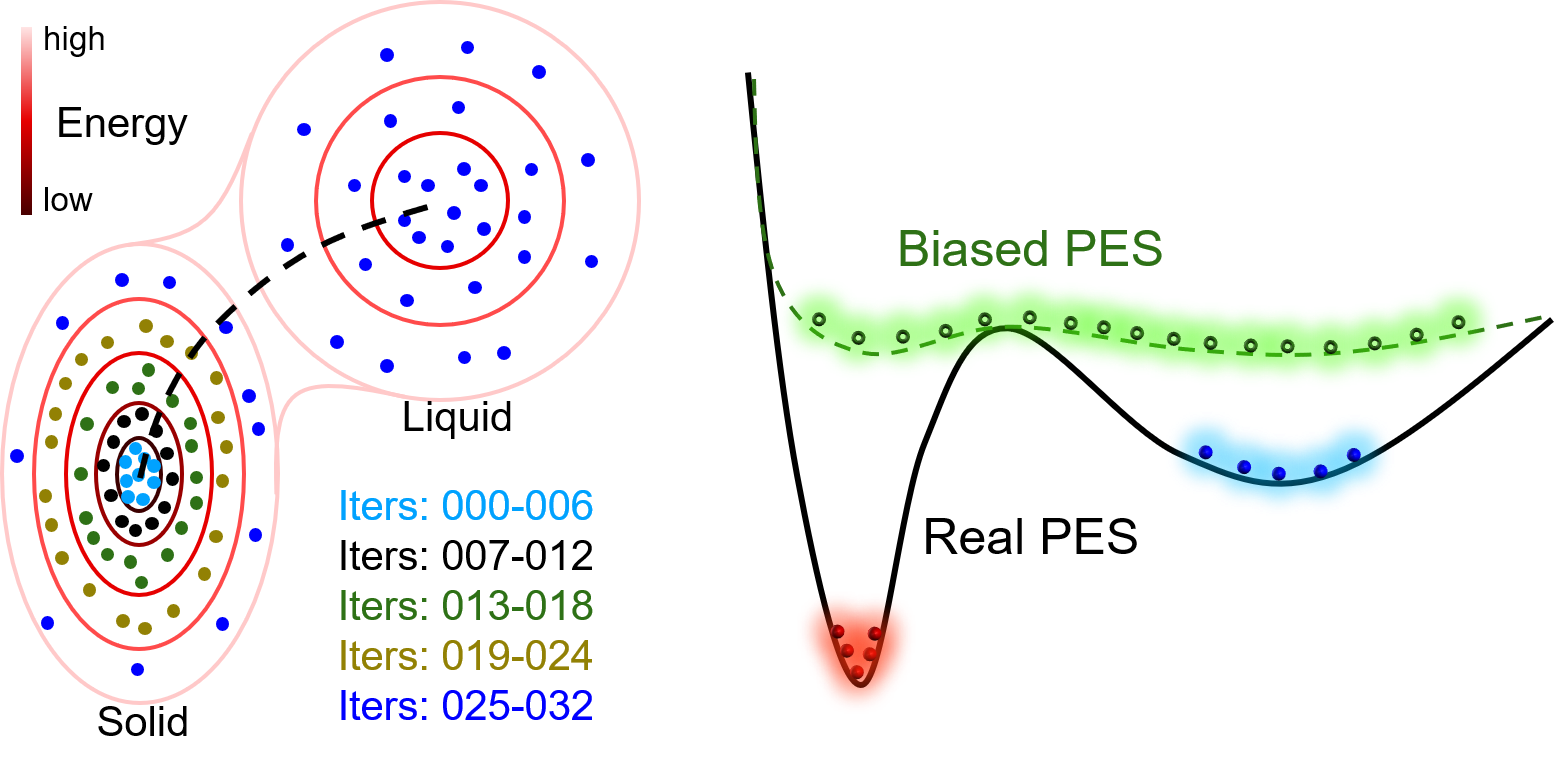 Example_Al
Example_Al
在第一种情况下,计算弹性性质只需要平衡态附近小形变构型。因此,只需要铝固态的平衡态附近的数据。运行DP-GEN从000到006对应的迭代可能就足够了。此外,如果我们想知道弹性性质的温度依赖关系,应该添加从007到024的迭代,进一步采样铝固态的高能状态(例如,热膨胀导致的晶格膨胀)。 在第二种情况下,图中的所有迭代都应该进行,对铝的固态和液态构型都进行采样。然而,如果我们关心液态铝的形核细节。数据集可能足以(或不足以)准确描述固液界面。通常情况下,如果材料中的键合方向性不强,例如,对于大多数金属而言数据集就足够了。有时,当材料中的键合具有强方向性时,情况并非如此。例如,Ga、Si等。然后,应在DP-GEN过程中结合增强采样的方法对一些特殊构型进行取样,例如,形核。如图所示可以沿图中的虚线进行多次模拟,以收集鞍点周围的构型。 在第三种情况下,需要基于缺陷构型(例如,空位、间隙、位错、表面、晶界)进行额外的DP-GEN过程。幸运的是,缺陷周围的一些局部原子结构可能类似于一些扭曲的晶格结构或非晶结构。因此,在采样期间,没有必要完全包括所有缺陷构型。 从这个简单的例子可以看出,如果能很好地定义一个问题的边界,大部分工作都可以节省下来。例如,如果我们只关心铝的弹性性质,就没有必要对熔体或缺陷构型进行采样,即便一般而言在开发金属的DP模型时都会对熔体和缺陷构型进行采样。相比之下,在开发化合物的DP模型时,尤其是对于那些具有复杂结构的化合物,只有在必要时才对熔体和缺陷构型进行采样。因此,在开始一个新问题之前,需要花一些时间思考问题的边界在哪里,以及应该覆盖多大的构型空间。 当我们得到一个新项目时,与其过于兴奋迫不及待地付诸实践,倒不如先将项目分割成一些更容易实现的小目标,这可能有助于整个项目的实施。例如,如果我们的最终目标是研究Al的缺陷,我们可以将整个问题分成几个部分并分阶段进行,如上文所述的阶段1、2和3。在每个阶段之后,我们可以获得一些里程碑成果,之后再顺利进入下一阶段。
翻译:史国勇、杜云珍,校对:戴付志